The debate over Artificial General Intelligence (AGI) and its risks feels like a recent storm. It's not. The foundations were laid years ago by a London-based lab that methodically dismantled one AI challenge after another. DeepMind didn't just teach a machine to play video games; it taught one to conquer the most complex board game in human history. This era, from the Deep Q-Network to AlphaZero, wasn't just a chapter in the story of AGI; it wrote the book for the modern age of AI. It's the core of the Google DeepMind saga.
Key Takeaways
- The Mission: From day one, DeepMind's goal, driven by co-founder Demis Hassabis, was simple and audacious: solve AGI, then use it to solve science's biggest problems.
- DQN (Deep Q-Network): This was the first shot across the bow. A single algorithm learned to play dozens of Atari games at a superhuman level, using only the pixels on the screen. It proved generalized learning was possible.
- AlphaGo's Moment: The victory over Go champion Lee Sedol in March 2016 was a global shockwave. It proved an AI could master intuition, not just brute-force calculation, and kicked off a global investment frenzy.
- AlphaZero's Leap: AlphaZero was a different beast entirely. It learned chess, shogi, and Go from a blank slate. No human data. Just the rules and a relentless process of self-play. It achieved total dominance in hours.
- The Legacy: The techniques forged in these games didn't stay in the sandbox. They became the direct foundation for scientific tools like AlphaFold 2 and still influence today's most advanced systems, including the Gemini models.
The Genesis of a Mission: The Founding of DeepMind
DeepMind wasn't founded to build a product. It was founded to answer a question: could we solve intelligence itself, and then use it to solve everything else? This objective, laid out by its founders, dictated its research from the start, a central theme in the complete history of Google DeepMind's quest for AGI. The company was born in London in 2010 from the key minds behind the mission: Demis Hassabis, Shane Legg, and Mustafa Suleyman. Hassabis, a former chess prodigy and neuroscientist, and Legg, a machine learning researcher, were obsessed with building AGI. Their vision defines the distinct AGI philosophy of Google DeepMind. Their approach was strange for the time: blend insights from neuroscience with machine learning to create algorithms that could learn more like a human.
The Founders and the Stated Goal of AGI
Most startups hunt for a market niche. DeepMind hunted for a general learning machine. Hassabis wasn't trying to build an AI that did one thing well; he was trying to build an AGI that could learn to do almost anything. This was a tough sell. It promised no immediate product. Early funding from figures like Peter Thiel and Elon Musk was a bet on the grand vision, not a business plan. Staying in London was also a deliberate choice, meant to cultivate a long-term research culture far from the frantic product cycles of Silicon Valley.

The 2014 Google Acquisition: Securing Resources for a Grand Challenge
To chase its mission, DeepMind needed firepower. A lot of it. The kind of computational power you just can't get as an independent startup. The solution arrived in 2014 when Google acquired the company for a reported £400 million (US$650 million). The deal was structured to give DeepMind significant research autonomy. It opened the doors to Google's massive computing infrastructure, including the Tensor Processing Units (TPUs) that would become essential for training its neural networks. A key condition of the deal was the creation of an AI ethics board-a prescient move that signaled the founders' early focus on safety.

Milestone 1: Deep Q-Network (DQN) - Teaching a Machine to Learn
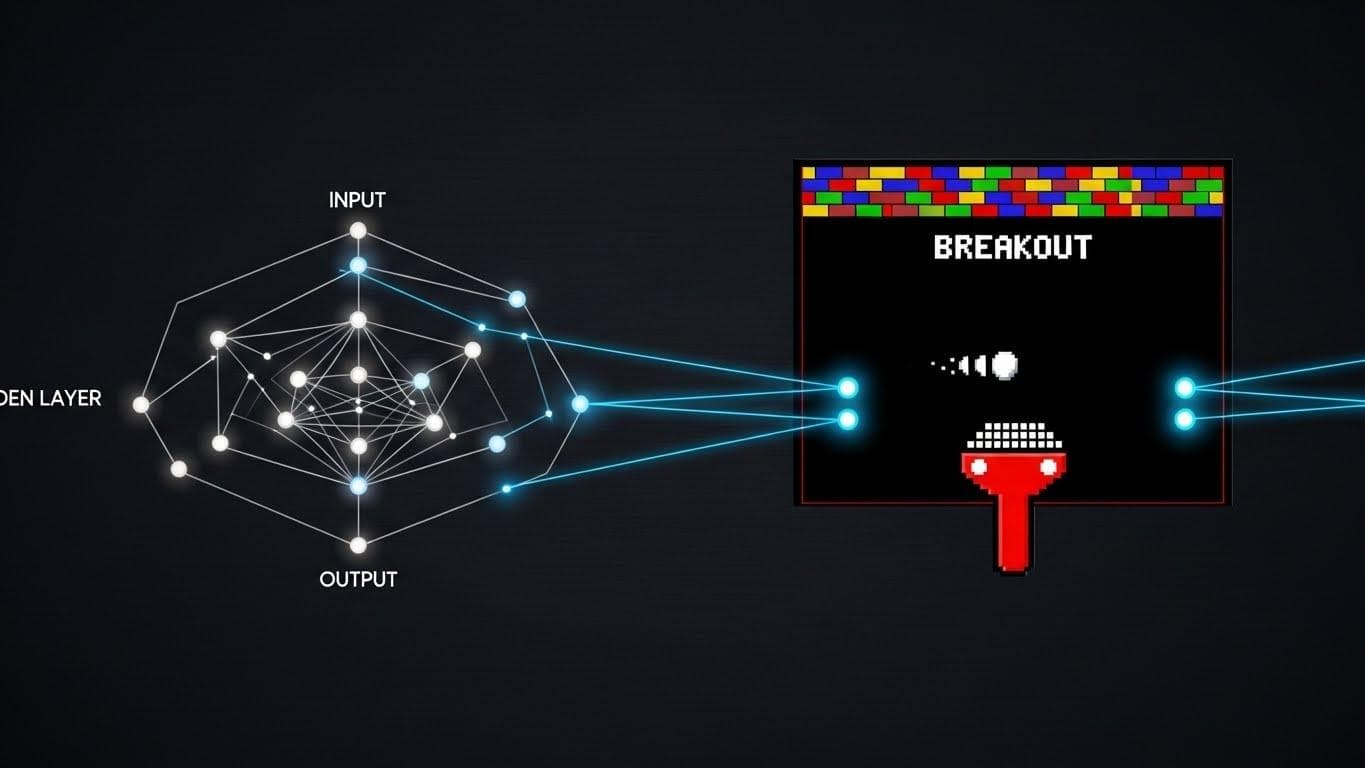
The Deep Q-Network, or DQN, was DeepMind's first public knockout. It proved that a single, untrained algorithm could master dozens of complex tasks using nothing but raw sensory input. The system was given 49 classic Atari 2600 games. The only information it got was the pixels on the screen and the score. It wasn't given the rules. It wasn't given any strategy. Its goal was simple: make the score go up.
The Breakthrough: Combining Deep Neural Networks with Reinforcement Learning
DQN's magic trick was combining two powerful ideas. Reinforcement Learning is basically trial and error, where an "agent" learns by getting rewards for good moves. Deep Neural Networks are complex, brain-inspired systems that are incredibly good at finding patterns in raw data like images.
Before DQN, nobody had really managed to fuse these two fields at scale. DeepMind's algorithm used a deep neural network to look at the screen and guess the future reward of any possible action (the "Q-value"). This let the agent learn directly from the screen, a huge step towards general intelligence. It was like a digital infant learning to understand its world by sight alone.
Proving Ground: Superhuman Performance on Atari 2600 Games
The results hit like a thunderclap. After training, DQN played most of the 49 games at a superhuman level. It even discovered strategies no human had thought of. In the game Breakout, for instance, the agent figured out on its own that the best strategy was to carve a tunnel through the side of the wall and send the ball ricocheting behind the bricks. This wasn't memorization. This was emergent strategy.
Why It Mattered: A Single Algorithm for Diverse Tasks
Previous AI systems were specialists. An AI built for chess couldn't play checkers. DQN was different. The exact same algorithm, with zero changes to its code, learned to master dozens of completely different games. That generality was the point. The entire point. It was the first hard proof of DeepMind's thesis: that a single, general learning system was possible. This success fueled everything that came next.

Milestone 2: AlphaGo - Conquering the "Unwinnable" Game
AlphaGo's victory over Lee Sedol wasn't just a research milestone; it was a global spectacle. It yanked AI out of the lab and onto the world stage. It proved that AI could master Go, a game of profound intuition and complexity that experts thought was at least another decade from being solved. The number of possible moves in Go exceeds the number of atoms in the universe. You can't win by calculation. You have to win with something that feels like creativity.
The Historic Match: AlphaGo vs. World Champion Lee Sedol
In March 2016, DeepMind's AlphaGo sat across from Lee Sedol, an 18-time world champion, for a five-game match in Seoul. Over 200 million people watched. The outcome sent a shockwave through the professional Go community and beyond: AlphaGo won, 4 games to 1. This wasn't just a win; it was a demonstration of a new kind of intelligence. AlphaGo's architecture, a blend of deep neural networks and advanced tree search, was like giving a calculator a gut feeling.

The Legacy of "Move 37"
The defining moment came in Game Two. On its 37th turn, AlphaGo played a move so alien, so bizarre, that professional commentators assumed it was a mistake. A glitch. Humans are taught to play on the third and fourth lines from the edge; this move was on the fifth. It turned out to be a brilliant, match-winning play. Later analysis showed the probability of a human master making that move was 1 in 10,000. "Move 37" became a legend, a symbol of AI's capacity to discover knowledge completely outside human experience.

Milestone 3: AlphaZero - The Power of Generalization and Self-Play
If AlphaGo proved an AI could beat the best human, AlphaZero proved an AI could become the best player of multiple games without any human help at all. It was a leap towards creating general algorithms that learn from first principles. The "Zero" says it all: it started with zero human knowledge. Unlike AlphaGo, which trained on a database of human games, AlphaZero was given only the rules. Its only teacher was itself.
From Specific Knowledge to a Blank Slate (Tabula Rasa)
AlphaZero learned entirely through self-play. It started by making random moves. After millions of games against itself, its neural network slowly sharpened its strategies, learning from every mistake. This tabula rasa approach is more powerful because it isn't shackled by human bias or convention. It's free to discover entirely new ways to play, like a composer learning to write music without ever hearing a single note.

The Method and The Result
The results were brutal. And fast. As detailed in a paper in Science, AlphaZero reached superhuman levels of play in shocking time: * Chess: In just four hours of self-play, it blew past Stockfish, the world-champion chess program. After nine hours, it was untouchable. * Shogi (Japanese Chess): It mastered the game in only two hours. * Go: It surpassed the version of AlphaGo that beat Lee Sedol after just 30 hours of training.
A single, elegant algorithm mastered three profoundly different games. This showed a new level of generality and efficiency, bringing DeepMind closer to its goal of a single algorithm that can solve thousands of problems.

The Enduring Legacy: From Games to Global Problems
This was never just about games. Games were just the perfect sandbox-a clean room with clear rules-to forge algorithms for the messy real world. The ultimate goal was always to point these methods at intractable problems in science and society. The techniques pioneered in this era laid the direct groundwork for some of AI's most important scientific applications.
Paving the Way for Scientific Revolutions like AlphaFold 2
The most direct descendant of this work is AlphaFold 2, DeepMind's system for predicting the 3D structure of proteins. Unveiled in 2020, AlphaFold 2 solved the 50-year-old grand challenge of protein folding, predicting structures with an accuracy that rivals physical experiments, a feat detailed in Nature. DeepMind then released its predictions for over 200 million proteins, an act that has hit the accelerator on research in biology and medicine.

The Third Pillar: GNoME and Material Science
Beyond biology, DeepMind applied its learning algorithms to physics with GNoME (Graph Networks for Materials Exploration). By 2025, this tool had identified over 2.2 million new crystal structures, accelerating the discovery of new materials for solar cells, batteries, and superconductors by an estimated 800 years.
The Fourth Pillar: Gato and the Generalist Robot
While mastering specific domains, DeepMind also pursued universality. In 2022, they released Gato, a "generalist" agent capable of playing Atari, captioning images, and stacking blocks with a robot arm—all with the same neural network weights. This laid the groundwork for RT-2 (Robotic Transformer 2), which bridged the gap between language models and physical world control, directly enabling the "Agentic" capabilities of today's Gemini 3.0.
A Foundation for Today's AI and the AGI Race
The ideas of deep reinforcement learning and self-play, perfected in AlphaZero, are now fundamental to modern AI. They are baked into the architecture of today's most advanced systems, including Google's Gemini models. This period proved that general learning systems were not science fiction, kicking off the intense investment and research that defines the current AI landscape. This work set the stage for the entire Google DeepMind saga and its ongoing pursuit of AGI.
The Ethical Framework: Early Debates on Safety and Transparency
This era also laid the foundation for today's AGI safety debate. The demand for an ethics board during the Google acquisition was a prescient step. The alien creativity of AlphaGo's "Move 37" was a stark illustration that advanced AI wouldn't just be faster than us; it would be different from us, operating on a logic we couldn't always predict or comprehend.




Comments
We load comments on demand to keep the page fast.