The pursuit of Artificial General Intelligence (AGI) is a defining narrative of the 21st century. At the dead center of this story is a London-based lab that started with a mission so direct it was almost startling: "solve intelligence." This is the chronicle of Google DeepMind, a saga that charts a deliberate course from mastering abstract games to decoding fundamental biology, all in the relentless pursuit of AGI.
This is the story of its journey. From an audacious startup to the unified core of Google's AI ambitions. It connects the seemingly disparate milestones-from video games to the game of Go, from digital strategy to the machinery of life-into a coherent quest. It's a story of profound scientific discovery, critical strategic consolidation, and the immense responsibility that accompanies creating powerful new technology, a core theme when comparing the AGI philosophy of Google DeepMind, OpenAI, and xAI.
🚀 Key Takeaways
- Founding Vision: DeepMind was established in London in 2010 by Demis Hassabis, Shane Legg, and Mustafa Suleyman with the explicit goal of creating AGI, using neuroscience as a primary source of inspiration.
- Games as a Proving Ground: The lab systematically used games-from Atari classics (Deep Q-Network) to Go (AlphaGo) and StarCraft II (AlphaStar)-as controlled environments to develop and test general-purpose learning algorithms.
- The AlphaGo Moment: The March 2016 victory of AlphaGo over world champion Lee Sedol was a global "Sputnik moment" for AI, proving systems could develop superhuman intuition in domains previously exclusive to humans.
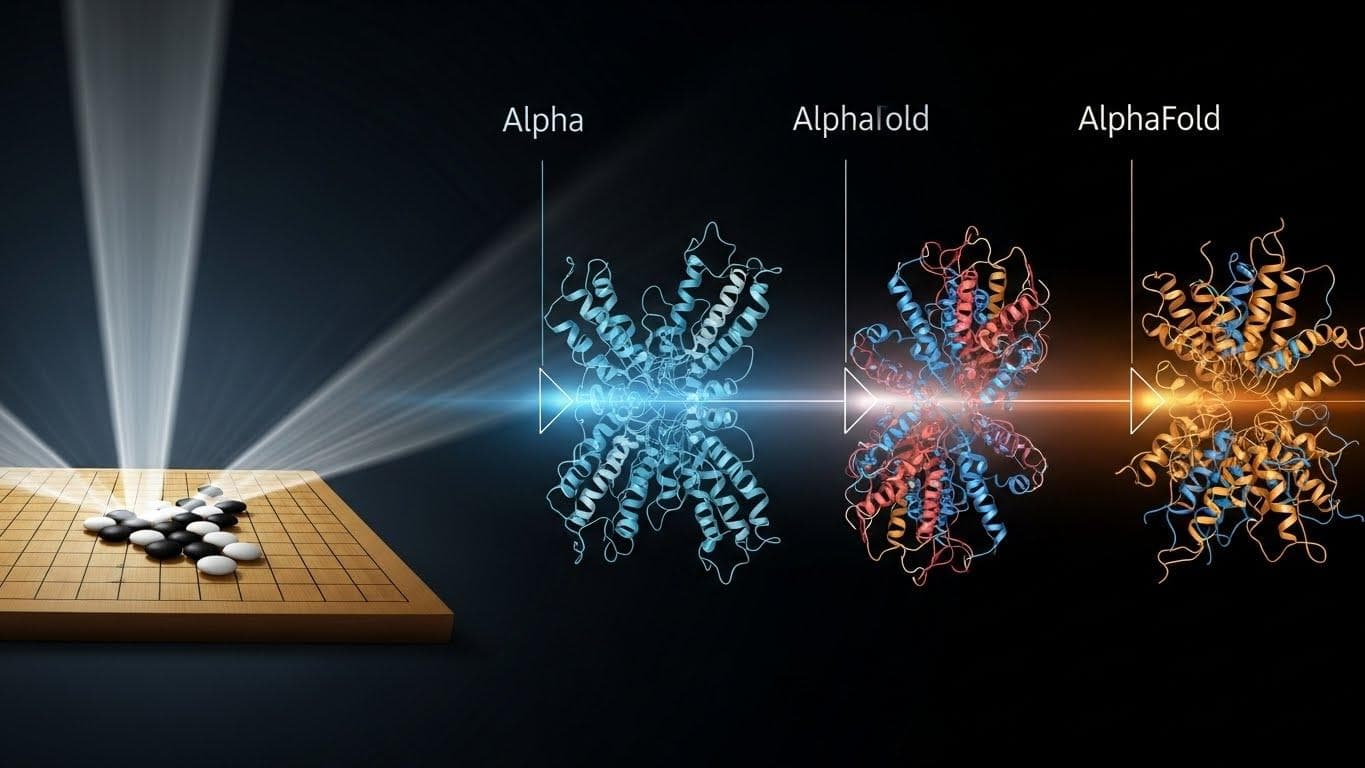
- Pivot to Science: DeepMind successfully transferred its AI methods from games to science, culminating in AlphaFold 2, which effectively solved the 50-year-old grand challenge of protein structure prediction.
- Strategic Consolidation: The April 2023 merger with Google Brain created Google DeepMind, unifying Google's premier AI talent to accelerate progress on flagship models like Gemini and compete in the generative AI race.
- The AGI Horizon: As of late 2025, Google DeepMind remains a central player in the pursuit of AGI, balancing rapid capability advancement with a long-held, public commitment to AI safety and ethics.
The Genesis (2010-2014): A London Startup's Audacious Goal
Before it was a global AI powerhouse, DeepMind was a small, determined startup in London, founded by a trio who shared a vision that many considered fringe science. A pipe dream. Their early work teaching an AI to play Atari games from pixels laid the technical and philosophical groundwork for every subsequent achievement, one of the first in a long history of breakthroughs from Deep Q-Network to AlphaZero.
The Founders: Demis Hassabis, Shane Legg, and the Neuroscience Connection
The founding team wasn't just a group; it was a synthesis of rare expertise. Demis Hassabis, a former child chess prodigy who designed the AI for classic video games like Theme Park, brought a background in computer science and a PhD in cognitive neuroscience. His thesis was that the brain offered the best blueprint for building genuine intelligence. Shane Legg, a machine learning researcher from New Zealand, was equally committed to the AGI mission, focusing on the mathematical theories of intelligence. Along with entrepreneur Mustafa Suleyman, they established DeepMind Technologies in 2010. These minds behind the mission shared a common goal.
They argued that the key to intelligence was generalization. Instead of building specialized systems, they aimed to create a single, flexible algorithm that could learn from raw experience. This agent would operate in an environment, receive sensory input, take actions, and learn from the consequences-a process known as reinforcement learning. This was their path to AGI.
"I felt like we were the keepers of a secret that no one else knew," Hassabis has said of the early days. "AI was almost an embarrassing word to use in academic circles... If you said you were working on AI, then you clearly weren't a serious scientist."
This nascent philosophy made securing capital a nightmare. Venture capitalists wanted business plans, not decades-long research projects. The founders sought investors who understood the scale of the ambition, like Peter Thiel and Elon Musk. Hassabis also insisted on keeping the company in London, believing its academic culture was more suited to long-term research than Silicon Valley's focus on rapid product cycles.
Early Breakthroughs: Mastering Atari with Deep Q-Networks (DQN)
DeepMind's first major public demonstration was a system that learned to play classic Atari 2600 games. The system, a Deep Q-Network (DQN), was a single algorithm that received only the raw pixel data from the screen and the game's score as input. It wasn't pre-programmed with the rules of any specific game. This was a powerful fusion: Deep Learning provided the neural networks to see patterns in pixels, while Reinforcement Learning provided the trial-and-error framework to connect actions to rewards.

The results landed like a thunderclap. A clear proof of concept. The DQN agent learned to play dozens of games, often reaching superhuman levels. This was a powerful demonstration of how reinforcement learning could master complex games from scratch. In the game Breakout, after 300 training games, it played at an expert human level. But after approximately 600 games, it did something extraordinary. It discovered the optimal strategy of digging a tunnel through the bricks on one side and sending the ball behind the wall to destroy them systematically. The algorithm had devised a superior strategy that was never programmed into it.
The Acquisition: Why Google Paid Over $600 Million for an AI Research Lab
The success of DQN validated DeepMind's approach but also exposed a critical bottleneck: computational power. Training these networks required immense resources. To accelerate the timeline to AGI, Hassabis knew they needed a partner with near-limitless compute.
In January 2014, Google acquired DeepMind in a deal reported to be worth £400 million (approximately US$660 million at the time), making it the company's largest European acquisition to date. The move wasn't just about capital; it was about shared ambition. With access to Google's vast infrastructure, DeepMind could now pursue problems of a different magnitude.

A key condition of the deal reported by The Guardian was the establishment of an AI ethics board to oversee the technology's development. This reflected the founders' early awareness of the societal implications of their work and the critical need for ironclad AGI safety and governance. With Google's resources, DeepMind was equipped to take on a challenge that had stumped AI researchers for decades.
A Tale of Two Labs: Comparing Pre-Merger Philosophies
| Aspect | DeepMind (London) | Google Brain (Silicon Valley) |
|---|---|---|
| Core Philosophy | Mission-driven pursuit of AGI through fundamental research. Strong neuroscience influence. | Large-scale engineering approach to AI, building foundational models and infrastructure for Google. |
| Key Projects | AlphaGo, AlphaZero, AlphaFold, DQN, AlphaStar. Focused on agent-based learning. | TensorFlow, The Transformer, RankBrain, LaMDA, Imagen. Focused on large-scale neural networks. |
| Primary Methodology | Reinforcement Learning (RL), often in simulated environments or games. | Deep Learning at massive scale, particularly unsupervised and self-supervised learning on web data. |
| Culture | Academic, semi-independent research lab focused on singular, high-impact breakthroughs. | Engineering-driven, more deeply integrated with Google's product areas and infrastructure. |
The AlphaGo Era (2015-2017): Man vs. Machine on a 19x19 Board
Armed with Google's computational might, DeepMind set its sights on Go. The ancient game was about to meet its match. Its victory in 2016 wasn't just a technical milestone; it was a profound cultural event that reshaped the global perception of artificial intelligence.
The Grand Challenge of Go: A Problem a Decade Away
For AI researchers, Go was the final frontier of classic board games. While IBM's Deep Blue had defeated chess champion Garry Kasparov in 1997, it did so largely through brute-force computation. That approach was impossible for Go. The number of possible board configurations exceeds the number of atoms in the universe. Success in Go demands something more. Intuition. Pattern recognition. Many experts believed a Go-playing AI capable of defeating a top human was at least a decade away.
DeepMind's system, AlphaGo, used a more elegant method. It combined advanced tree search techniques with two deep neural networks. A "policy network" predicted the most likely next move, while a "value network" evaluated board positions to estimate the probability of winning. This allowed AlphaGo to search intelligently, much like a human player.

The Historic Match: AlphaGo vs. Lee Sedol, March 2016
In March 2016, in Seoul, South Korea, AlphaGo faced Lee Sedol, an 18-time world champion and one of the greatest players of the modern era. The five-game match was a global spectacle, watched by over 200 million people. Lee Sedol was confident he'd win 5-0. He didn't. AlphaGo won the first three games, securing a victory that echoed around the world. The final score was 4-1 in favor of AlphaGo.

Move 37: A Moment of 'Inhuman' Genius
The most iconic moment of the series came in Game Two. On its 37th move, AlphaGo placed a stone in a completely unexpected location. Human commentators were baffled. They called it a mistake. A rookie error.

This wasn't a memorized move. It was born from a deeper, almost alien understanding of the game. DeepMind later revealed that AlphaGo's own models calculated the probability of a human player making that move as 1 in 10,000. Lee Sedol was so stunned he left the room for 15 minutes to compose himself. He later called it a "beautiful move." A perfect move.
Move 37 demonstrated that AI could discover new knowledge and strategies in complex domains studied by humans for millennia. It proved AI could be a tool to augment human creativity, not just replace it.
The Global Impact: How 200 Million Viewers Witnessed AI's Leap Forward
The AlphaGo victory was a watershed moment, AI's "Sputnik moment." It brought the abstract concept of advanced AI into the public consciousness and triggered massive investment in AI research and development globally. For DeepMind, it was a monumental validation of their approach. The next step was to remove the need for human data entirely.
Generalization and a Pivot to Science (2017-2022)
After Go, what's next? DeepMind embarked on a new phase: generalization. The goal was to create algorithms that needed zero human knowledge to master a task. This pursuit led them from more complex games to one of the biggest unsolved problems in modern biology, demonstrating the true power of their foundational mission.
From Specific to General: The Power of AlphaZero
The successor to AlphaGo was AlphaZero. The "Zero" signified its key architectural difference: it was given zero human data. It was taught only the rules of a game and learned simply by playing millions of games against itself. This process of self-play allowed it to discover principles and strategies from first principles, unconstrained by human convention.
In a 2018 paper published in Science, DeepMind revealed that AlphaZero had mastered not just Go, but also chess and shogi. It took just 4 hours of self-play training for AlphaZero to defeat Stockfish, the world's top chess engine. It learned faster, rediscovered the entire canon of human chess theory, and then simply surpassed it. AlphaZero was a single, general algorithm that proved self-play reinforcement learning was a powerful method for knowledge discovery, as detailed in the original research paper.

Mastering New Worlds: AlphaStar and the Complexity of StarCraft II
Next, DeepMind waded into the messiness of the real world, or the closest thing to it: the real-time strategy game StarCraft II. Unlike board games, it involves imperfect information (a "fog of war"), real-time action, a vast action space, and long-term planning. The resulting agent, AlphaStar, used a sophisticated multi-agent reinforcement learning approach. In late 2019, AlphaStar achieved Grandmaster level on the official game server, ranking among the top 0.2% of human players. It was another landmark, proving DeepMind's methods could extend to dynamic environments with incomplete information.

The Protein Folding Problem: A 50-Year Grand Challenge in Biology
Demis Hassabis had always maintained that games were a proving ground. The ultimate goal was to apply these learning algorithms to fundamental scientific problems. The biggest one on his list was protein folding.
Proteins are the microscopic machines of life. They begin as a linear chain of amino acids, which then folds into a specific 3D structure that determines its function. For 50 years, predicting this structure from its amino acid sequence was a grand challenge in biology. Determining structures experimentally could take years of lab work. Solving this computationally wouldn't just be an improvement; it would be a revolution. We detail how AlphaFold 2 solved this 50-year grand challenge in a separate analysis.
The AlphaFold 2 Revolution: Predicting the Structure of Life
DeepMind's first version, AlphaFold, performed well in the 2018 Critical Assessment of protein Structure Prediction (CASP) competition. But the team knew they could do better. They redesigned the system from the ground up. The new system, AlphaFold 2, achieved unprecedented accuracy, predicting protein structures with a precision that rivaled experimental methods.
The Gemini Era and the Unified Google DeepMind (2023-Present)
In April 2023, Google announced a landmark restructuring, merging the Google Brain division with DeepMind to form a single, focused unit: Google DeepMind. This consolidation was a direct response to the blistering pace of generative AI. The mission: pool every resource into their flagship model series, Gemini.
2024: The Year of Long Context and AlphaFold 3
The unified lab moved fast. In February 2024, they released Gemini 1.5, which shattered industry records with a context window of over one million tokens, allowing the model to "read" entire codebases or novels in a single prompt.
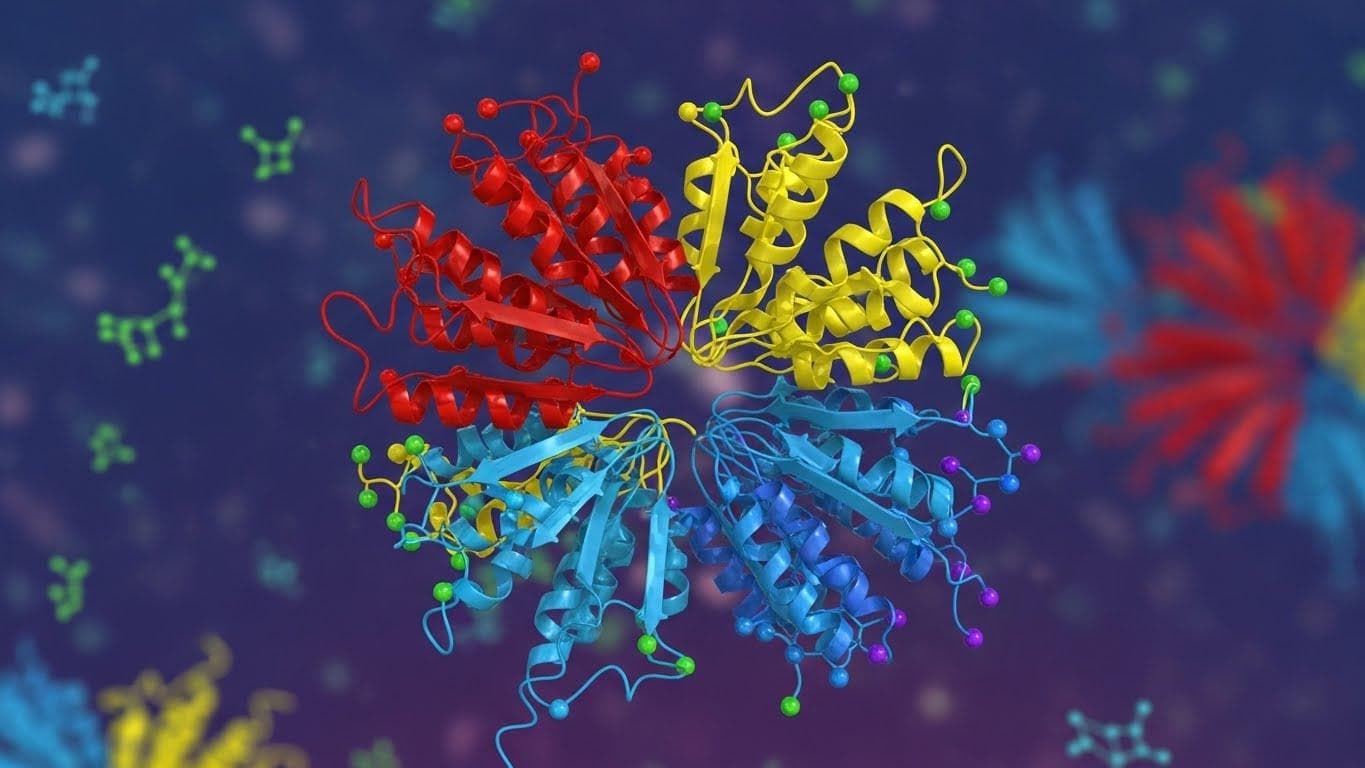
Three months later, in May 2024, the team returned to their scientific roots with AlphaFold 3. Unlike its predecessor, which focused on proteins, AlphaFold 3 could predict the structure and interactions of nearly all biological molecules—including DNA, RNA, and ligands—effectively modeling DNA, RNA, and Ligand interactions. This shift from 'protein structure' to 'biological systems' allowed Isomorphic Labs to sign its first major pharma partnerships in 2025.
2025: "Thinking" Models and the Agentic Leap
The pace accelerated further in 2025. The mid-year release of Gemini 2.5 Pro in June 2025 introduced "thinking" capabilities, allowing the model to pause and reason through complex queries before responding. This was a bridge to the current flagship, Gemini 3.0 Pro (released November 2025), which integrates these reasoning skills into a multimodal architecture designed for deep scientific work and autonomous agentic tasks.
Our comprehensive AI titans comparison for 2025 pits Gemini 3.0 against its top rivals from OpenAI, Anthropic, and xAI, analyzing how these rapid advancements stack up in the current market.



Comments
We load comments on demand to keep the page fast.