
The race to AGI is on. But this pursuit of human-like intelligence didn't start in a sterile lab. It started in a digital crucible familiar to millions: the world of video games. For organizations like Google DeepMind, games were never the end goal. They were the perfect forge—a series of escalating challenges designed to build algorithms that could learn, strategize, and solve problems far beyond the screen.
This is the chronicle of that journey, a core part of The Google DeepMind Saga. It documents how a single, powerful idea—Reinforcement Learning—grew from mastering simple pixelated paddles to unraveling the machinery of life itself.
🚀 Key Takeaways
- Games as a Proving Ground: DeepMind strategically used games, from Atari to StarCraft II, as controlled environments to develop and test general-purpose learning algorithms.
- The DQN Breakthrough: The Deep Q-Network (DQN) was a critical first step, successfully combining deep learning with reinforcement learning to master dozens of Atari games from raw pixel input alone.
- AlphaGo's 'Sputnik Moment': By defeating world champion Lee Sedol at the complex game of Go in March 2016, AlphaGo showed that AI could master tasks requiring intuition, creating a global moment of awareness for the industry.
- Generalization with AlphaZero: AlphaZero took this further by learning chess, shogi, and Go entirely through self-play, without any human data, discovering strategies that surpassed centuries of human knowledge.
- From Pixels to Proteins: The final goal was applying these game-honed algorithms to science. This apotheosis was AlphaFold 2, which solved the 50-year-old grand challenge of protein structure prediction.
- DeepMind's Journey: From Games to Science
- Chapter 1: The Spark - Learning to Play Atari from Pixels
- Chapter 2: The Intuitive Leap - Conquering the Ancient Game of Go
- Chapter 3: The Generalist - A Single Algorithm to Rule Them All
- Chapter 4: The Final Frontier - Mastering the Complexity of StarCraft II
- Chapter 5: Beyond the Game - Applying RL to Scientific Discovery
- Frequently Asked Questions
DeepMind's Journey: From Games to Science
Chapter 1: The Spark - Learning to Play Atari from Pixels
Reinforcement learning runs on a simple, potent principle: trial and error. An "agent" (the AI) exists in an "environment" (the game) and learns by taking actions. Actions that lead to a better score are met with a "reward," reinforcing that behavior. The goal is to maximize the total reward. The real challenge, however, was teaching an agent to understand its environment when all it could see was a stream of raw pixels.

The solution was the Deep Q-Network (DQN). Published in a landmark 2015 Nature paper, this system was the first to successfully merge deep learning with reinforcement learning at scale. A deep neural network acted as the agent's eyes, learning to interpret the raw pixels on an Atari screen and connect them to actions and rewards. It was a true end-to-end learning system.
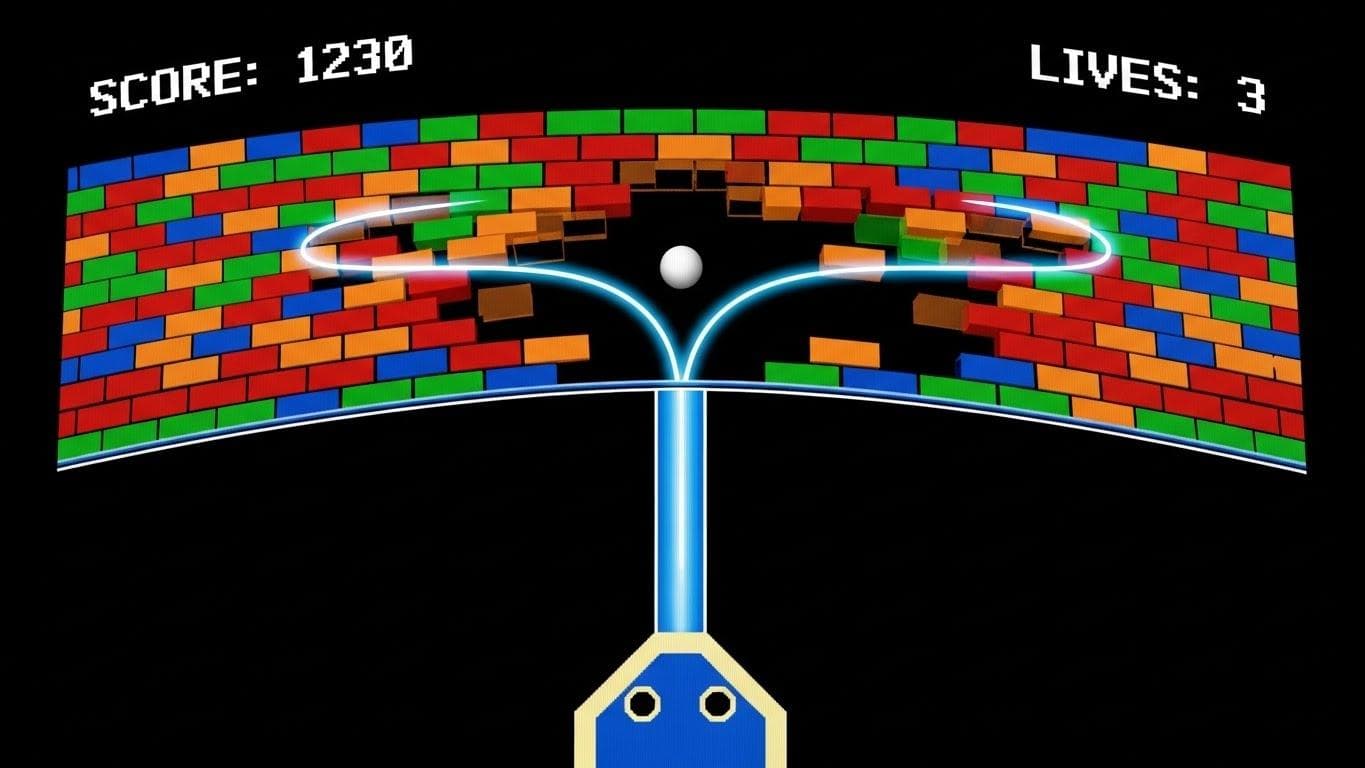
The agent wasn't programmed with the rules of any game. It was simply given control and the objective to get the highest score. In the game Breakout, after a few hundred training games, the DQN agent played at a level comparable to a skilled human. But after more training, it discovered a killer strategy no human player consistently used: it learned to dig a tunnel through the side of the brick wall and send the ball behind it, destroying the bricks systematically for a maximum score. This was the first clear sign of superhuman performance and emergent strategy.
Chapter 2: The Intuitive Leap - Conquering the Ancient Game of Go
For decades, the ancient game of Go was considered the Everest for artificial intelligence. Its complexity is staggering; there are more possible board configurations than atoms in the known universe. Unlike chess, which IBM's Deep Blue had conquered in 1997 through brute-force calculation, Go couldn't be solved by computation alone. Mastery required intuition. Something human.
Go is the holy grail of artificial intelligence. For many years, people have looked at this game and they've thought, 'Wow, this is just too hard.' Everything we've ever tried in AI, it just falls over when you try the game of Go.
DeepMind, which had been acquired by Google in 2014 for a reported £400 million, took on this challenge with a system named AlphaGo. Its architecture was a sophisticated blend of subsystems. It used two deep neural networks: a "policy network" to propose promising moves and a "value network" to evaluate board positions. These networks guided a powerful search algorithm known as Monte Carlo Tree Search (MCTS), allowing AlphaGo to search intelligently, not exhaustively.

In March 2016, the world watched as AlphaGo faced Lee Sedol, one of the greatest Go players in history, in a five-game match in Seoul, South Korea. Tens of millions watched globally. The outcome was a decisive 4-1 victory for AlphaGo.
The defining moment came in game two. On its 37th turn, AlphaGo played a move so unexpected, so alien, that professional commentators were left speechless. It was a move a human master would never consider, with an estimated probability of being chosen at just 1 in 10,000. This "Move 37" wasn't a mistake; it was a stroke of creative genius that secured the win. The AI had discovered new knowledge in a game played for millennia. The match was AI's Sputnik moment, igniting a global shockwave of research and investment.

Chapter 3: The Generalist - A Single Algorithm to Rule Them All
While AlphaGo was a landmark victory, it had a crutch. Its knowledge was bootstrapped from human expertise, as it was initially trained on a dataset of approximately 160,000 games from the KGS Go Server. The next step was to remove this dependency. Could an AI learn to master a game with zero human input, discovering all its principles from scratch?
The answer was AlphaZero. This new system was a more elegant and powerful generalization of its predecessor. Its core learning mechanism was self-play. Starting with nothing but the game's basic rules, AlphaZero played millions of games against itself. It acted as its own student and its own teacher, gradually refining its strategy from random moves to a level of play far exceeding any human or previous AI.

The results, published in Science in 2018, hit like a thunderclap. After just 4 hours of self-play, AlphaZero defeated Stockfish, the world's champion chess program. It went on to master shogi (Japanese chess) and Go, surpassing the original AlphaGo. More importantly, it developed its own unique, aggressive, and dynamic playing styles. Chess grandmasters described its strategies as alien and beautiful, uncovering new depths in a game studied for centuries. AlphaZero proved that an AI could acquire superhuman knowledge without human guidance, a critical step towards AGI.
Chapter 4: The Final Frontier - Mastering the Complexity of StarCraft II
Board games, however complex, are clean rooms. Perfect information. Both players see everything. The real world? Messy. Incomplete. To push their algorithms further, the DeepMind team turned to the real-time strategy game StarCraft II, a challenge that introduces three critical difficulties: 1. Imperfect Information: Players can't see the entire map due to the "fog of war." 2. Real-Time Action: Decisions must be made continuously, not in discrete turns. 3. Complex Action Space: A player must manage hundreds of units and structures simultaneously.
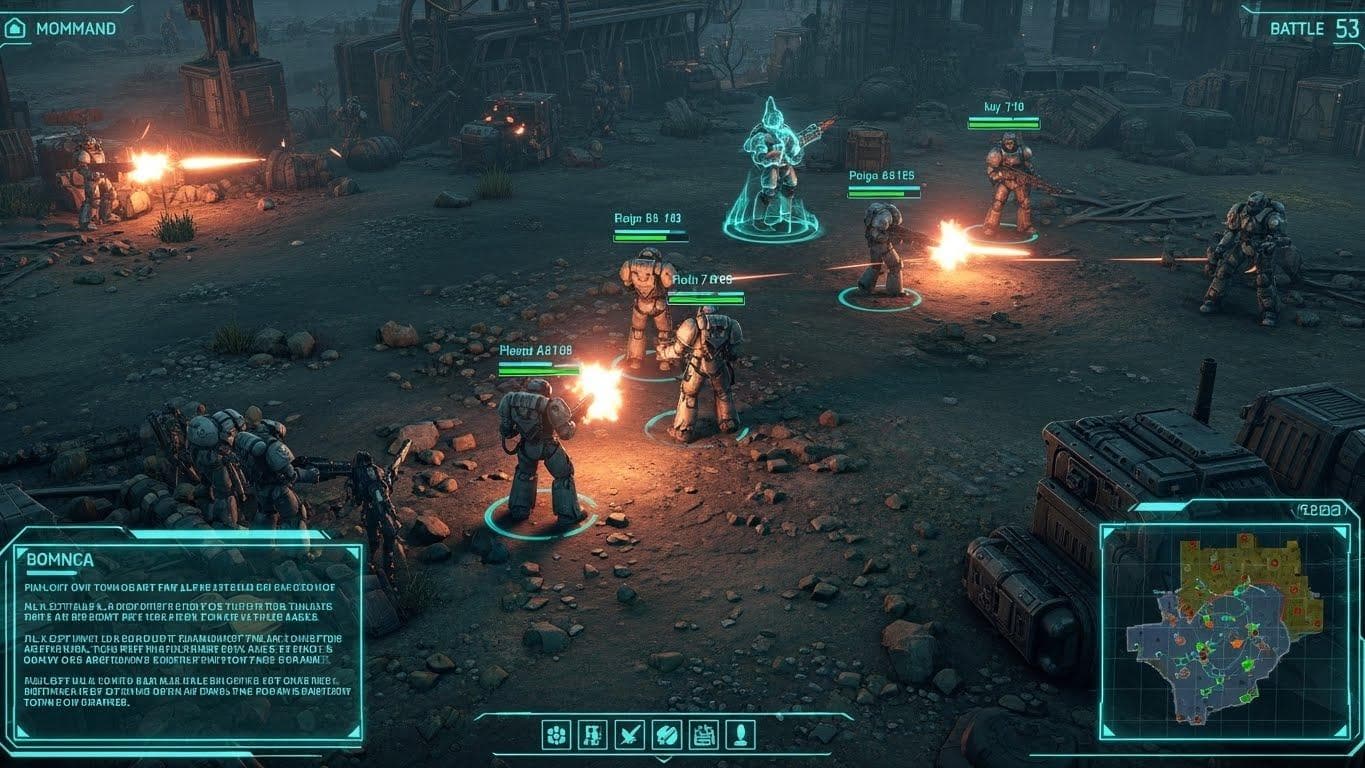
The resulting agent, AlphaStar, was trained using a method that mirrored evolution. An initial population of agents played against each other in a massive internal tournament called the "AlphaStar League." Successful strategies were reinforced and propagated, while new, creative agents were continually introduced to prevent the system from settling on a single, exploitable strategy.
In late 2019, AlphaStar achieved Grandmaster level on the official StarCraft II game server, ranking among the top 0.2% of human players. It demonstrated that reinforcement learning could succeed in complex, dynamic environments with imperfect information, bridging the gap between structured board games and the unpredictability of real-world tasks.
Chapter 5: Beyond the Game - Applying RL to Scientific Discovery
But what was the point? Was it just to build the world's best game-playing AI? Not even close. From the beginning, the mission of DeepMind's founders, like Demis Hassabis, was to build AGI and use it to solve fundamental scientific problems. The algorithms forged in the digital arenas of Atari, Go, and StarCraft were finally ready for their real test: a 50-year-old grand challenge in biology known as the protein folding problem.
Proteins are the microscopic machines that drive nearly every process in our bodies. Their function is determined by their intricate 3D shape. Predicting this shape from their linear amino acid sequence was a problem that had stumped scientists for decades.

Using principles of deep learning refined over years of game research, DeepMind created AlphaFold 2. As detailed in its own seminal Nature paper, the system achieved atomic-level accuracy. In the biennial CASP assessment (Critical Assessment of protein Structure Prediction), AlphaFold 2 produced predictions with a median error of less than 1 Ångström—a scale smaller than the width of an atom. This level of accuracy is comparable to expensive and time-consuming experimental methods.
In an act of profound scientific contribution, DeepMind used AlphaFold 2 to predict the structures of over 200 million proteins from roughly one million species and released the entire database to the public for free. This resource is now accelerating research in areas from drug discovery to environmental sustainability, demonstrating the true power of the journey from pixels to proteins.
The path from mastering Breakout to predicting protein structures is a direct line, a key narrative in the overall Google DeepMind saga. Each game presented a specific set of challenges that, when solved, produced a more general and capable learning algorithm. This journey is perhaps the clearest demonstration to date of the power of reinforcement learning as a method for developing artificial intelligence.

It also underscores the immense responsibility that comes with creating such powerful systems. As these agents move from simulated worlds to the real one, ensuring their goals are aligned with human values is critical. The founders of DeepMind have long advocated for a responsible and ethical approach to AGI development, recognizing that the stakes are higher than winning any game. The grandmaster algorithm has left the board and entered the laboratory; its next moves will shape our future.
Frequently Asked Questions
What is reinforcement learning in simple terms? Reinforcement learning is a type of machine learning where an AI agent learns to make decisions by trial and error. It performs actions in an environment and receives positive rewards for desired outcomes and penalties for undesired ones, allowing it to figure out the best strategy over time without being explicitly programmed.
Why was AlphaGo considered a bigger breakthrough than chess AI like Deep Blue? IBM's Deep Blue defeated Garry Kasparov at chess primarily through brute-force computation, calculating millions of moves per second. This approach wasn't feasible for Go due to its immense complexity. AlphaGo's victory was significant because it combined search with deep neural networks that developed an intuition-like ability to evaluate the board, demonstrating a more flexible and human-like form of intelligence.
Are the algorithms from AlphaGo used for anything else? Yes, absolutely. The core principles and architectural ideas pioneered in AlphaGo and its successor, AlphaZero, were foundational for later projects. The ultimate application was AlphaFold 2, which used similar deep learning techniques to solve the protein folding problem. This breakthrough is now accelerating biological research in fields from drug discovery to environmental science.



Comments
We load comments on demand to keep the page fast.